Linux server performance: Is disk I/O slowing your application?
If your Linux server is bogged down, your first step may often be to use the top command in the terminal to check load averages. However, there are times when top shows very high load averages even with low CPU ‘us’ (user) and high CPU ‘id’ (idle) percentages.
This is the case in the video below; load averages are above 30 on a server with 24 cores, but the CPU shows around 70 percent idle. One of the common causes of this condition is disk I/O bottleneck.
What is I/O wait bottleneck?
Storage I/O is input/output (or write/read) operations on a physical disk (or other storage, for example, disk or SSD). Requests which involve disk I/O can be slowed dramatically if CPUs need to wait on the disk to read or write data. I/O Wait is the percentage of time the CPU had to wait on storage.
Let’s look at how we can confirm if disk I/O is slowing down application performance by using a few terminal command-line tools (top, atop and iotop) on a lemp-installed web server.
Check disk I/O in 2 mins (video).
Using TOP command – load averages and wa (wait time)

As per the video above, when you enter top, you’ll first glance to the upper-right to check load averages. In this case, it’s very high and thus indicates a pileup of requests. Next, we will most likely glance at the CPU and mem horizontal lines near the top, followed by the %CPU and %MEM columns, to get an idea of which processes use the most resources.
While in top, you will also want to look at ‘wa’ (see video above); it should be 0.0% almost all the time. Values consistently above 1% may indicate that your storage device is too slow to keep up with incoming requests. Notice in the video that the initial value averages around 6% wait time.
However, this is averaged across 24 cores, some of which are not activated because the CPU cores are not nearing capacity. So we should expand the view by pressing ‘1’ on your keyboard to view ‘wa’ time for each CPU core when in use. As per the screenshot above, there are 24 cores, from 0 to 23.
Once we’ve done this, we see that ‘% wa’ time is as high as 60% for some CPU cores! So we know there’s a bottleneck, a major one. Next, let’s confirm this disk bottleneck.
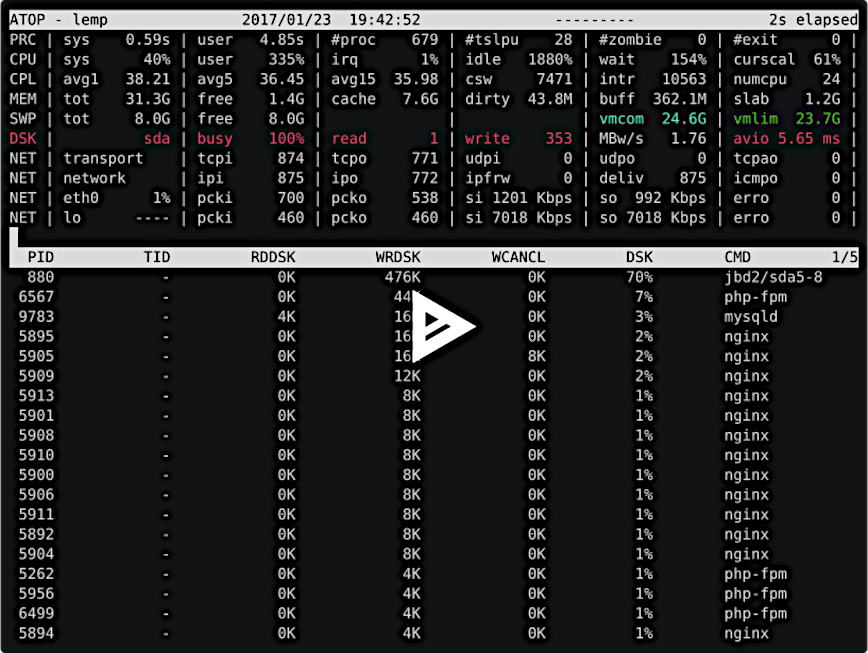
Using ATOP command to monitor DSK (storage) I/O stats

Using atop, next, we see that the storage device is 90 to 100 percent busy. This is a severe bottleneck. The effect is that requests are blocked until disk I/O can catch up. While in atop, press ‘d’ to view the processes and PIDs which are using disk I/O.
Here we see MySQL, Nginx, and PHP-FPM, which are necessary processes, and I would have to write another article about reducing disk I/O on high-traffic L*MP servers. In short, be careful that Nginx (or Apache), MySQL, and PHP-FPM’s access and error logs are not set up to write too frequently to disk and you also want to avoid storing cache (e.g., Nginx cache) to disk in very high concurrent traffic environments.
In addition to LEMP services, also notice ‘flush-8:0’ (a PHP cache issue) and jbd2/sda5-8 (traced to access/kernel logs) along with their PIDs.
On this server, I performed a quick SSD benchmark after stopping services and noticed that disk performance was abysmal. The results: 1073741824 bytes (1.1 GB) copied, 46.0156 s, 23.3 MB/s. So although reads/writes could be reduced, the problem here is extremely slow disk I/O.
This client’s web host provider denied this and stated that MySQL was the problem because it often grows in size and suffers OOM kill. On the contrary, MySQL’s growth in memory usage was a symptom of disk I/O blocking the timely return of MySQL queries and with MySQL’s my.cnf max_connections setting on this server being way too high (2000), it also meant that MySQL’s connections and queries would pile up and grow way beyond the available server RAM for all services.
It was growing to the point where the Linux Kernel would OOM kill MySQL. Considering MySQL’s max allocated memory equals the size of per-thread buffers multiplied by that ‘max_connections=2000’ setting, this also left PHP-FPM with little free memory as it piled up connections waiting on MySQL < disk. But with MySQL being the largest process, the Linux kernel opts to kill MySQL first.
Using IOTOP command for real-time insight on disk read/writes

iotop watches I/O usage information output by the Linux kernel. It displays a table of current I/O usage by processes or threads on the system. I used the command: iotop -oPa. Here’s an explanation of those options. -o, –only (Only show processes or threads doing I/O, instead of showing all processes or threads.
This can be dynamically toggled by pressing o.) -P, –processes (Only show processes. Normally, iotop shows all threads.) -a, –accumulated (Show accumulated I/O instead of bandwidth. In this mode, iotop shows the amount of I/O processes have done since iotop started.)
Look at the ‘DISK WRITE’ column; these are not very large figures. At the rate they increment, a reasonably average-speed storage device would not be busy with some kernel logging and disk cache. But at < 25 MB/s write speed (and over-committing memory), disk IO is maxed out by regular disk use from Nginx cache, kernel logs, access logs, etc. The fix was to replace the storage with a better-performing device with faster write speeds than an SD card.
Of course, MySQL should never be allowed to make more connections than the server is capable of serving. Also, the workaround of throttling incoming traffic by lowering PHP-FPM’s pm.max_children should be avoided or only temporary because this means refusing web traffic (basically moving the location of the bottleneck).
Thankfully, the above case of a storage device being this slow is not common with most hosting providers. If you have a disk with average I/O, you could also use Varnish cache or other caching methods, but these will only work as a shield when fully primed. If you have enough server memory, always store everything there first.
Also, look at this list of the top 50 APM tools.
Here are some additional command-line tools used:
iostat, dstat, lsof, vmstat, nmon, sar, iptraf iftop, netstat, lsof, pvdisplay, lspci, ps.
Results from a quick dd disk write benchmark on a small StackLinux SSD VPS: [root@host ~]# dd if=/dev/zero of=diskbench bs=1M count=1024 conv=fdatasync 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB) copied, 0.751188 s, 1.4 GB/s
Also, see Your Web Host Doesn’t Want You To Read This: Benchmark Your VPS.
Published: July 9th, 2017 | Last updated: June 16th, 2025

Knowing how to track down the reason for slowness on a system is a good skill to have. There are many possible causes, and it can be tricky sometimes.
I recently had to check this for my server and sure enough, it was the case. I had thought that it was something I was doing wrong since I recently moved it. Varnish cache is something I have used in the past and I am considering using it again. I don’t want this issue to pop up again.
Good tips here. I took a look at iotop after reading this and it’s very helpful.
What are your suggestions on the IO settings in MariaDB/MySQL? I’m really not sure what to set these to and I can’t find a conclusive answer anywhere.
@coastL Check out this post: MySQL Database Performance: Avoid this common mistake