Cloudflare outage on Nov 18, 2025 – Waking up to a broken internet
Cloudflare is one of those companies most people never think about, yet on mornings like this it suddenly becomes the main character. Its network sits in front of millions of sites, speeding them up, filtering junk traffic, and quietly handling DNS and security for everything from tiny blogs to giant social platforms. When that layer stumbles, it feels less like “a provider had an issue” and more like the internet itself forgot how to get out of bed.
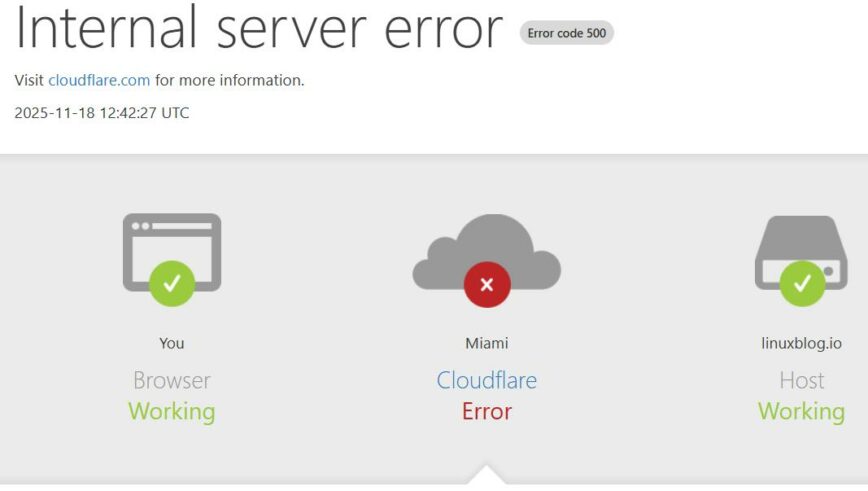
Most of us woke up this morning to error messages from many websites. I first wondered if my home network was acting up, but after a handful of minutes it became clear it wasn’t me: Cloudflare itself was having a bad morning. Large parts of the internet are struggling to load, and Cloudflare has acknowledged the issue and is investigating the problem.
In practical terms, if your browser needed to talk to Cloudflare before it could talk to a website, there was a good chance you are staring at a 500 error instead of getting anything done.
Sites struck by the outage
This is a major outage; to put it in perspective, there were over 11,500 reports of problems with X alone. Ironically, the outage tracking sites like Downdetector, and pingdom.com, were taken offline by today’s Cloudflare outage. Dozens of popular apps and websites suddenly fell silent: X, OpenAI, Canva, Discord, DigitalOcean, Medium, Feedly, Figma, 1Password, Trello, Namecheap, Postman, Vercel, and many more.
As the outage rippled outward, more names were added to that list. Reports and status pages called out problems at Spotify, Facebook, Zoom, and a growing group of AI tools including ChatGPT, Gemini and Perplexity, along with regional services and hosting dashboards that sit behind Cloudflare’s edge.
From the operator side, r/sysadmin, Hacker News and other hosting forums lit up with the usual mix of hugops and gallows humor as admins compared notes. One redditor said, it’s “the sound of a thousand devs all simultaneously crapping their pants cos they think they’ve pushed a dodgy build. Followed by the sound of a thousand devs all breathing a sigh of relief cos someone else messed up and not them.”
What Cloudflare says

Cloudflare is aware of a major global glitch and has launched an investigation. As of this writing, it’s still ongoing, and we still don’t know why it happened. Cloudflare’s bulletin simply said it was “working to understand the full impact” and would provide updates. This incident comes on the heels of recent AWS and Azure outages, which makes us wonder if there’s a shared cause (for now that’s speculation, though). I, like many, am now refreshing every 15 to 30 minutes the status feed and my Cloudflare.com account.
Some admins have noticed that the timing overlaps with scheduled maintenance windows in several data centers and are already wondering if something there went sideways, but until Cloudflare ships one of its usual long-form postmortems, that stays in the speculation bucket.
Learning from the last outage
This is a reminder that the modern internet is a relatively small number of very complex platforms stitched together with a lot of trust and a lot of assumptions. Most days that holds up well, and nobody notices. But on days like today, the curtain slips, and we get to see just how closely everything is tied together.
This kind of failure isn’t unprecedented. Not so long ago (June 2025), Cloudflare had a similar scare. Back then, experts traced the problem to Google Cloud. Cloudflare’s own spokesperson told reporters flatly, “This is a Google Cloud outage,” explaining that a few Cloudflare services running on Google’s infrastructure had failed.
That time, services were soon restored once Google resolved its problem. Today’s outage is still under investigation, but history suggests we might expect a quick fix once the root cause is identified. For example, if it turns out to be a configuration bug or human error, then engineers usually patch it within hours.
If you zoom out further, this fits a longer pattern. Previous big Cloudflare incidents have been triggered by everything from faulty router configurations to problematic BGP announcements and code pushes that behaved badly at global scale. The specifics change, yet the common theme is pretty simple: highly automated, globally distributed systems behave beautifully most of the time, right up until one small mistake gets amplified everywhere at once.
For now, I’ll get back to work and watching the Cloudflare status page. If you had trouble accessing big sites today, know that it’s not just you. In the meantime, let’s hope the internet gets “coffee” of its own and wakes up soon.

We are also noticing this significantly here. Atlassian is causing problems and more.
It looks like they are finally, after ~ 3 hours, getting on top of it:
downdetector.com was also down because of Cloudflare. The irony!
Per usual, a really transparent postmortem has been posted:
As mentioned in another topic, this impacted us for at least a half day, with ripple effects going on for several additional hours. I think that the fundamental components of the components we refer to as the Internet need a lot more redundancy and a lot less dependence on one to three large companies where some poorly tested change brings down the entire infrastructure.
Very bad choice of activities, but CloudFlare should not have such a controlling influence over a network that affects not only communications, but also tens, if not hundreds of billions of dollars of business each day.
There’s been a lot going on in the last few days. AWS, Cloudflare—our partner company’s data center isn’t working…
Follow up from me: 4-5 days later, things from my end seem 100% back to normal. Based on seat of the pants observations, even 24 hours later, there were occasional blips or sites that had failed to reset or restore themselves following the incident.
On a probably unrelated matter, but one that REALLY seemed to expose our device, seven years ago we moved into our retirement community and we have a Spectrum cable box. I’ve been complaining to my wife how terrible the technology is, calling it twenty year old trash. Anyway, the CloudFlare incident seemed to do something else; it might be a coincidence, but those power issues may have brought the device close to final (but not 100%) end of life.
If there is a positive on this barely related topic, the Spectrum Internet/Cable vendor DOES have a new generation, much smaller, current generation box now available that supports HDMI and streaming connections. I want to get one of those devices as a replacement, and if/when I do, I’d be glad to write a completely separate article about it; meanwhile, the RELATIONSHIP of all of this to the CloudFlare issue is that the problems occurred BEGINNING with the CloudFlare incident!